
“I thought I would definitely win… So I said yes, without much hesitation.”
So Lee Sae Dol, the former 18-time Go world champion, told Google Korea in an interview in March. He was speaking of agreeing to a professional Go match in 2016, against an AI system called AlphaGo.
Considered the finest player of his generation, Lee’s defeat in three straight games made international headlines, though no one was as shocked as Lee himself.
Go, which originated in China some 2500 years ago, is generally considered the most complicated game on Earth. Played on a 19-line-by-19-line board, there are more possible positions than atoms in the universe (a 10 with more than 100 zeroes after it), making its mastery seem more of an art than a science.
At least, until the AI was developed that beats humans virtually every time.
The development of AlphaGo (leading to the AlphaZero AI), is just one example of the way that gaming and AI have been entwined since the beginning.
Today we look at innovations in self-learning AI systems, being tested (once again) with games, and where AI self-improvement is on the road to autonomous systems that will revolutionize everything from medical research to everyday business practice.
The Evolution of AI With Gaming
When playing digital games, we may deal with supposedly autonomous, fictional characters, navigate interactive (changing) narratives, and compete against seemingly intelligent, non-living opponents.
But even aside from the kind of automated behavior that’s long been labeled AI in gaming, the freedom of movement and action in the 3D spaces of some open-world games prove highly useful for testing more autonomous AI behavior in sandboxed safety.
[Even the hardware used to build today’s generative AIs comes from games, as covered in length in a prior edition of The PTP Report.]
Go, as discussed above, was a real-world game chosen by AI developers as a benchmark test, for its complexity. After an IBM machine first beat chess champion Garry Kasparov in 1997, it seemed the next logical step.
But for some twenty years, AI systems couldn’t get beyond the amateur level.
That changed with DeepMind’s AlphaGo. Starting in 2014, it was developed using neural network concepts and outplayed all existing systems. In 2015 it defeated the European Go champion, and in 2016 defeated world master Lee Sae Dol.
AlphaGo looked in many ways like we’d expect of a generative AI system of today: trained on volumes of available Go game data, including some 30 million moves from high level players. All combined, when it defeated Lee, he described it playing in a style he’d never seen.
Yet over the intervening years, it has also been defeated, replaced by a version called AlphaGo Zero, that didn’t learn from human players at all.
AlphaGo Zero knew nothing about Go but the rules: it learned wholly by playing. Over just three days, it played 5 million games against itself in a flurry, learning from its own mistakes. It soon defeated AlphaGo, which had been two years in development and months in training.
Google’s DeepMind also makes extensive use of digital games, from Starcraft to Doom, No Man’s Sky to Goat Simulator 3, and the results have been profound, with the lessons learned being applied in all manner of systems:

The technique used by AlphaGo Zero (followed by AlphaZero) is self-play AI, a reinforcement style of learning based on doing, rather than consuming existing knowledge about the thing itself.
In the examples above, we see these lessons applied across the board (one of the earliest improvements came in the form of enhanced video compression for Google streaming via Youtube, Twitch, Google Meet).
Today we see AlphaZero being paired with additional models to attain even more advanced forms of self-learning. One example is AlphaProof, which alongside AlphaGeometry 2 managed 4 of 6 problems at the impressive International Mathematical Olympiad (akin to a silver medal), far exceeding prior AI capacities.
Outside of the math domain, the achievement is noteworthy as it moves these models a step closer to applying generalized logic.
AlphaProof uses what’s called a neuro-symbolic approach, combining both with an aim to merge strengths (and remove weaknesses) of each.
It builds on AlphaZero by combining it with another model trained on math statements in the programming language Lean. Able to translate from natural language to handle mathematical proofs, it springs from their successes in reinforcement learning AI with Go.
In entertainment, this also makes news for its use in systems like GameNGen, which can generate all new levels of existing games like Doom on the fly, predictively, without any game engine at all.
In published research, the developers detail their architecture, which uses reinforcement learning (like AlphaZero) to train an agent to play the game, keeping its episodes and observations and using them to train a generative model. Unlike prior games built with scripted levels, this builds all new levels, on the fly.
These innovations are part of a move that will translate far beyond gaming and mathematics, applicable to AI for factory automation and autonomous vehicles, and augmented reality that can adapt on the fly, enabling education and hands-on training and support, not to mention the possibility of real, collaborative work at distance.
Instructable AI
DeepMind’s Scalable, Instructable, Multiworld Agent (SIMA) uses open-world games to create a generalized agent that can do anything we can in simulated 3D environments.
Following natural language instructions, this AI system can accomplish a huge range of tasks across a spectrum of worlds, not focused on winning or losing, but instead on achieving a user’s stated goal.
Drawing from just two inputs (visuals of the game world and the player instructions), these agents are trained across environments, outperforming those trained on just a single game.
They’re proving capable of performing nearly as well in games and environments they’ve not yet seen before. As demonstrated below, language is broken down and tied to a finite number of possible actions across environments:
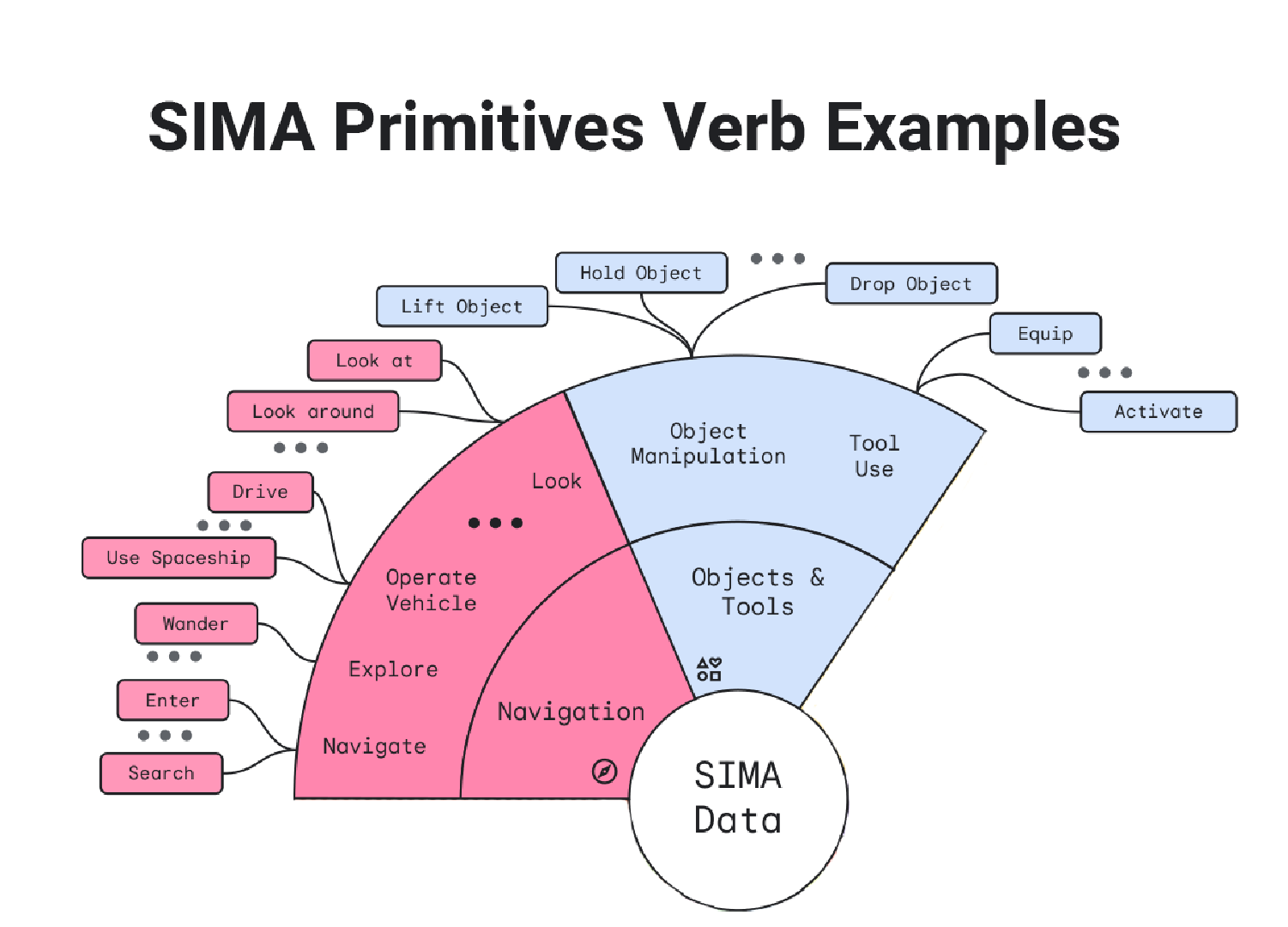
This SIMA AI development is another step towards highly generalized agentsthat can function autonomously to achieve stated goals.
And while we’ve focused here on DeepMind projects, similar AI development is underway at numerous AI companies.
With its project codenamed Strawberry (formerly Q*), OpenAI is reportedly nearing the ability to also handle more generalized logic, aiming for AI that can undertake multiple steps of planning, potentially akin to AlphaProof, and extending into research.
As an OpenAI spokesperson told Reuters, who broke initial news on Strawberry:
“We want our AI models to see and understand the world more like we do. Continuous research into new AI capabilities is a common practice in the industry, with a shared belief that these systems will improve in reasoning over time.”
And as profiled in one of our prior articles, OpenAI also uses games such as Minecraft in their testing and development.
Limits
While these achievements are striking in terms of games, with their fixed (however expansive) rules like Go and limited environments, or via math problems which are either right or wrong, there remains a significant step to being broadly applicable.
Even with a capacity to string multiple actions together for a single goal, the binary nature of the problems makes it clear when it’s succeeded or failed. For general tasks and logic, systems must handle trade-offs, with a range of nuance in potential outcomes, especially in problem domains such as law and healthcare, and to truly consider complex business decisions.
Without the ability to sort absolutely between right and wrong, the ability to apply logic from one arena to another remains challenging.
They also have some way to go to handle what Northwestern professor Kristian Hammond describes as “Type 2” reasoning in the article: OpenAI’s Strawberry: A Step Towards Advanced Reasoning in AI.
Like the “multi-hop” problems that plagued early versions of ChatGPT (and still can to a lesser extent), generative AI systems struggle to take multiple steps without explicit instruction (or “hop” from one answer to the next question, taking what they need to know). This is one reason generative AI outputs are often better after initial outlines in writing, or when prompted to detail their specific, chain-of-thought rationale for an answer.
They “think” as they create output, instead of considering a problem in any depth first, which is Type 1 reasoning, or fast and direct.
As Hammond writes:
“One of the more interesting aspects of these two modes of thought is that we tend to use Type 2 reasoning to both debug and train ourselves.”
As Northwestern professor Hammond writes of OpenAI’s Strawberry, maybe it will be:
“…a step towards an AI that doesn’t just answer questions but contemplates them, unpacks them, and then merges multiple functionalities and data sources into a cohesive whole to solve them. The pivot point will be when machine learning models begin to teach themselves how to think, and that’s when we’ll truly be entering the realm of AGI.”
Conclusion
“I was surprised because it played so well. Even now, when I look back at the early moves, it is very surprising. Back then I thought, ‘Uh oh, we have a problem…!’”
This is how the best Go player of his generation, Lee Sae Dol, described his bafflement at playing AlphaGo, back in 2016.
After processing the initial losses, he played it again and won, and to this day remains the only human to have successfully beaten AlphaGo, across 74 official games.
Lee thinks he could have played better, understanding what he was facing. He believes AI has changed the game of Go and will also change the entire world.
Drawing from games, built to master them, and tested within their bounds, AI remains inextricably linked with gaming. By looking at its breakthroughs there, we get glimpses of where it is heading.
And Lee Sae Dol wants everyone to be ready—more ready than he was. In interviews given this year, he says he remains optimistic, believing AI will create jobs even as it eliminates them.
He points out that it was people who created the game Go, just as people created the AI system that has mastered it.
His concern is less about AI’s capacity, and more that we are ready for it
References
Defeated by A.I., a Legend in the Board Game Go Warns: Get Ready for What’s Next, The New York Times
Google’s GameNGen: AI breaks new ground by simulating Doom without a game engine, Venture Beat
New AI model “learns” how to simulate Super Mario Bros. from video footage, Ars Technica
DeepMind hits milestone in solving maths problems — AI’s next grand challenge, Nature
Scaling Instructable Agents Across Many Simulated Worlds, arXiv:2404.10179 [cs.RO]
Exclusive: OpenAI working on new reasoning technology under code name ‘Strawberry’, Reuters


