
If you used AI much at all, you’ve been lied to. Told that glue is tasty on pizzas, that daily rocks can be good for you, or that US presidents from centuries past have recently graduated from the University of Wisconsin.
This is nothing new, of course, but for a technology with so many applications, it’s proving disturbingly hard to get rid of.
When computer and cognitive scientist Douglas Hofstadter worked with OpenAI’s GPT-3 back in 2022, he reported numerous ways to get it to answer with garbage, with one famous example being:
Q: When was the Golden Gate Bridge transported for the second time across Egypt?
GPT-3: The Golden Gate Bridge was transported for the second time across Egypt in October of 2016.
Still it continues apace. In the legal field, where adoption’s high (3/4 of lawyers report planning to use genAI), hallucinations continue to wreak havoc, with a recent study from Stanford and Yale (published April 2024) reporting a disturbingly high rate of fabrication with GPT-4 and other public models (“at least 58% of the time”).
And yet in surveys by Tidio, for example, 72% of users report trusting AI to provide “reliable and truthful information,” even as 77% of them admit to being deceived by hallucinations.
The general view of AI hallucination risks seems to be that they’re a growing pain, but one we will soon move past. Even as researchers are not so sure.
One thing is certain, with so much at stake, billions will be spent to improve generative AI’s factual reliability.
In this week’s edition of The PTP Report, we focus on preventing AI hallucinations: why they persist, the best performers, and current research reducing their impact.
Hallucinations: Why AIs Just Can’t Stop Lying
Any discussion of “hallucination” has to begin with a definition of the term. We all agree it includes cases where an AI returns information that is factually untrue.
But should it only include when an AI returns verifiably wrong facts from a prompt that does not?
Should “hallucination” also refer to partial truths, misinterpretations, and omissions?
Some particularly stringent definitions require an AI’s response to include only verifiably correct information, and all of it, every single time, regardless of prompt.
We see wildly varied hallucination rates largely for this reason (as in the study cited above), depending on what one’s end goal is.
But regardless of how tight the filter being used, hallucinations continue for a number of factors, including:
- As prediction machines geared to anticipate what’s next, their factuality is relative to the information they have to predict from. LLMs don’t analyze, relative to other subjects, much data they have on a given subject.
- The quality of training data is essential, as garbage in means garbage out. But LLMs cannot have unlimited data on any subject, and all data is subject to bias. A shortage of new, available data means AI-generated synthetic data is also being included, increasing the potential for falsehood propagation.
- Calibration, with things like word choice and style irrelevant (and often at odds with) the quality of the facts being output. If we expect an AI to write well in a matter of seconds, it may come at the cost of giving us the best information, according to research by Santosh Vempala at Georgia Institute of Technology, as reported by Scientific American.
Also scale is highly relevant. Even as relative rates are brought down by AI hallucination solutions, the increasing level of adoption means the number of falsehoods continue to rise.
(Consider estimates of ChatGPT API requests reaching into the trillions per day: if your definition means 2-3 falsehoods per 100, you’re in the tens of billions of hallucinations, daily.)
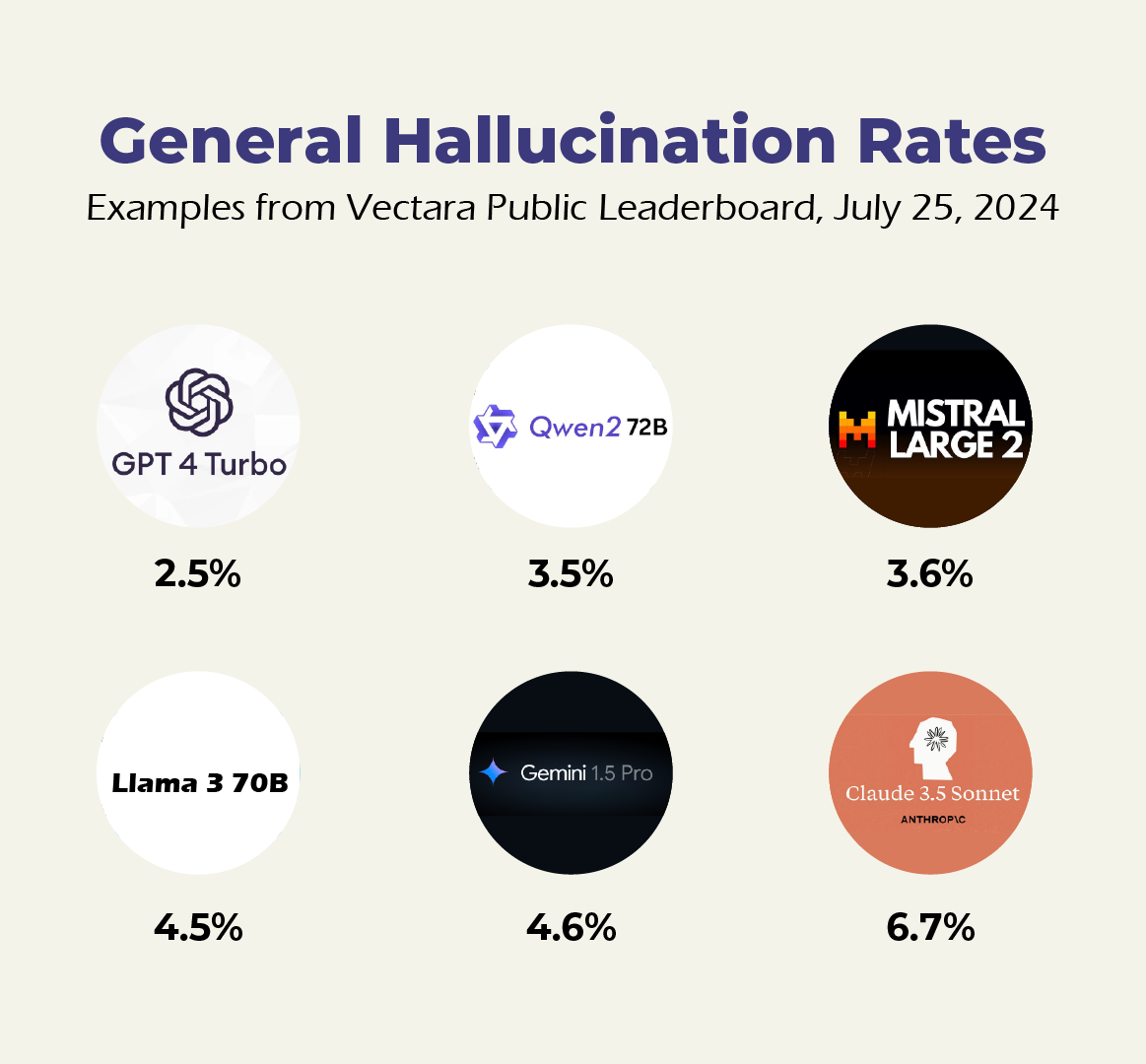
AI company Vectara has emerged a leader in hallucination evaluation, working from the Hughes Hallucination Evaluation Model (HHEM). Their leaderboard, like the LYMSYS Chatbot Arena Leaderboard, keeps updated evaluations of hallucination rates for public models, with some selections indicated above.
(Note these models were chosen for comparison with models below, in RAG, except for GPT 4 Turbo, which is the overall leader.)
Approaches for Improving AI accuracy
Game Theory
One method for enhancing AI models is currently being tested by researchers at MIT and is called the consensus game. As reported by Quanta Magazine, this approach makes use of game theory, pitting an LLM against itself, as so-called generative (open-ended questions that end with one answer) and discriminative (choosing a best between options) divisions often result in different answers to factual queries.
Through this game, the LLM must come to consensus to win, in a process that can teach the AI to be more consistent across these divisions. This work can also be fast, and reasonably light-weight computationally.
Another version is called the ensemble game, where a larger LLM works with smaller LLMs as either allies or adversaries. Again the goal is for the LLM to “win” games, by choosing the right answers from the wrong.
[For more on the deep relationship between gaming and AI, check out our recent article on gamification in the AI age.]
The Thermometer Approach
Also at MIT (in conjunction with the MIT-IBM Watson AI Lab) is another approach geared at preventing AI misinformation that works by combining multiple models, large and small.
This approach takes on the issue of calibration. With massive, universal LLMs being geared to handle all manner of tasks, it can be hard to adjust them for specific purposes (as what may work well for one fails more regularly for another).
A smaller, lighter-weight Thermometer model in this case evaluates the larger, more universal model’s level of certainty for given answers, seeing where it may be overconfident on false answers. This smaller model then acts like a tuner, allowing the adjustment of the larger model for the task at hand.
While still not universal in application, it’s showing great progress for specific use cases, with these adjustments producing better uncertainty measures in the large LLM.
Tuning Prompts
The future of generative AI may not involve text-based prompting at all.
Seemingly minor prompt differences can now produce a wide variation of answers, often for reasons that are baffling to users, with many of these not even understood by the creators of AI systems (such as the case of Star Trek or thriller-framed prompts resulting in better math responses than those without, or in getting improvements by suggestions an AI will “have fun” in the process).
Even asking an LLM to explain its reasoning (aka chain-of-thought), which often produces better results, doesn’t always. The confusion comes in part from assuming an LLM understands language like people do, when in fact they’re transforming language to math and back in the end.
One method for lowering hallucinations springs from this: generating superior prompts, by having AI systems themselves assist with the process. By scoring prompts to determine what works better or worse, these systems can optimize the prompting process itself.
As detailed in reporting by the IEEE Spectrum, these solutions augment user requests with an “autotuning” process to replace, or beef-up, a user-provided prompt.
While initial research in this field has proven very successful, making such systems at sufficient scale and consistency across domains remains a significant challenge.
Retrieval-Augmented Generation (RAG)
The most common AI hallucination prevention techniques in use today stem from a process called retrieval-augmented generation (RAG). While there are numerous varieties, at its core RAG refers to using external data sources as boost or check on the answer generation process.
This can include leading the LLM to select answers from a subset of data, such as a database. Forced to limit its options, the possibility of far-flung falsehoods comes down.
But the applications and quality of these systems vary, and even in experiments cannot completely remove hallucinations.
Even tracking hallucination rates through RAGs is challenging, with a variety of evaluations, such as the Hallucination Index by Galileo, (below from July 2024), that use proprietary metrics to identify best and worst hallucinators using RAG under a series of conditions, including small, medium, and large contexts, which see variations in results.
These are their winners across all measures in the current report:

As you can see comparing this to the general hallucination rates measured by Vectara above, there’s a wide variety in performance between general and RAG-improved solutions.
Conclusion
As AI is increasingly central to our daily lives, it’s tempting (and even sometimes rewarding) to anthropomorphize it, thinking of it as a logical mind that helps us get what we need done.
But AIs don’t speak English, and their very nature as autocomplete mechanisms makes them prone to falsehood.
The best means available now for stopping AI hallucinations may be to accept this, and instead focus on AI error containment, rather than prevention in the first place.
By using varied systems, verifying results, getting sources, requiring reasoning, and carefully prompting, we can use it safely, even as new AI development strategies work to increasingly diminish hallucination’s impact.
Someday AI systems will no doubt check other AI systems, further reducing the need for human involvement, but until that time, accepting them for what they are may be our best defense.
References
AI Chatbots Will Never Stop Hallucinating, Scientific American
Artificial neural networks today are not conscious, according to Douglas Hofstadter, The Economist
When Machines Dream: A Dive in AI Hallucinations [Study], Tidio
Method prevents an AI model from being overconfident about wrong answers, MIT News
Game Theory Can Make AI More Correct and Efficient, Quanta Magazine
Evolution of RAG in Generative AI, Aporia
AI on Trial: Legal Models Hallucinate in 1 out of 6 (or More) Benchmarking Queries, Stanford HAI
Improving Self Consistency in LLMs through Probabilistic Tokenization, arXiv:2407.03678 [cs.CL]
AI Prompt Engineering Is Dead, IEEE Spectrum


