
As we enter 2025, I think it’s fair to write that there’s little debate about these two things:
1. Quality AI results require quality data, aka garbage in, garbage out. Or, in the words of “the father of the computer” Charles Babbage:
“On two occasions I have been asked, “Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?” … I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question.”
2. AI innovations are being developed and released at a rate that’s much faster than most anyone (including tech companies) can keep up with.
Add to this examples, such as one posted on LinkedIn by Shadi Copty, a senior director of engineering at Meta, that demonstrate how fine tuning a small LLM (1B to 3B parameters, runnable on desktop machines) for specific use cases improves accuracy by up to 60%, and the importance of having focused control over your data may be greater than ever.
This is supposed to be the year of the AI agent, where we will see increasingly autonomous AI solutions, likely taking advantage of access to multiple such models for specific purposes, but again, whether they reason or work like autocomplete, they will only be as smart, or dumb, as the information you provide them.
To prepare, organizations need valid use cases, a handle on security, and also today’s focus: AI-ready data.
[For more on practical AI implementation, check out this edition of The PTP Report.]
The Benefits to Data Warehouse AI Integration
AI solutions impact the flow and use of data in numerous ways, from automating Extract, Transform, Load (ETL) to identifying issues across sources to improving schema mapping to transforming predictive analytics right from the data warehouse.
There’s little more satisfying than seeing exponential drops in runtime for a critical query over large datasets, and of course AI can help here, too, analyzing historical patterns, optimizing plans, and identifying bottlenecks.
AI monitoring is improving, and making more accessible (and fast), the capacity to identify anomalies in data use, too, be it transactional or operational, and can also monitor access controls, and logs (whether they’re structured, semi-structured, or even, increasingly, unstructured).
One of the most commonly teased benefits of AI is the ability to directly query with natural language. Long the goal of data visualization providers, the idea of having a literal conversation with your data is extremely tantalizing, and could, in theory, transform reporting and the way we consume data overall.
But this opens the door to loads of potential problems, from the risks of poor performance to the leaking of personally identifiable information (PII) to the possibility of bad inferences or even inaccurate results.
AI Adoption Challenges
AI can help load, maintain, monitor, and analyze your data, but it’s new and changing fast, making the practical points of connection frustratingly mobile targets.
Failures can be costly, too. In a 2024 survey by Wakefield Research, more than half of respondents acknowledged data quality issues costing their companies at least $100,000 in just the last six months.
And 68% weren’t fully confident in their data’s reliability for the planned AI use cases.
More broadly, Gartner estimates data quality issues cost organizations $12.9 million a year on average.
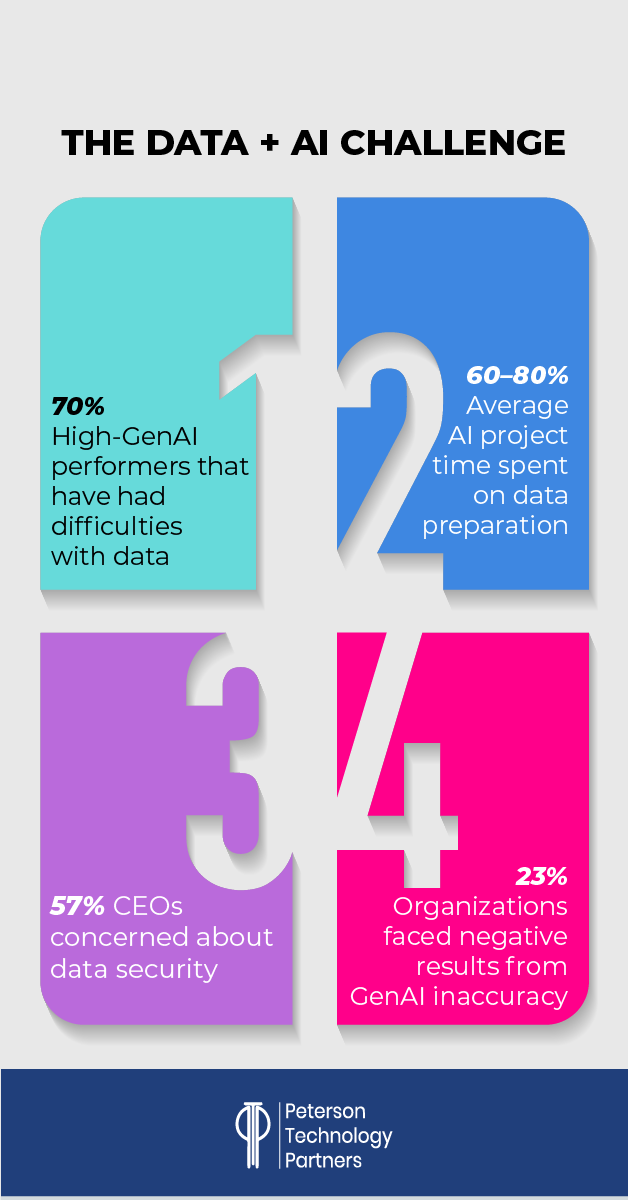
Having a data warehouse that’s really ready for AI integration depends on specific use cases, as it’s seeing broad application. Removing anomalies and outliers, for example, is essential to some use cases, but by obscuring representative samples of collection, can impair others.
Preparing Data for AI
While it’s true you can’t conduct a single series of steps to ensure you’ve got AI-ready data frameworks across the board, there are consistent issues that limit AI effectiveness, such as having variation across silos, insufficient (and inconsistent) metadata, and a failure of understanding.
In general, the goal for AI readiness spans these areas:

Whether you’re tuning your own solutions with open-source models, in an experimental phase testing new releases, implementing solutions in isolated sandboxes, or working with a third-party provider, you can still prepare using several data inventory best practices.
Specify Use Cases
There’s arguably no more easily written-than-done tip than this one.
Because while we’ve all experienced AI wonder at creation of a video, drafting of email, sudden bug find in code, or unexpected data insight, as a whole, the technology often feels incomplete or too vast, making it hard to get our minds around, let alone integrate to solve a highly specific business need.
For those just getting started, automation of repeated tasks that are safe, either by human checking or low risk data, are ideal places to get started and explore the possibilities.
Your data prep needs are going to vary whether you’re planning to use AI for predictive maintenance in manufacturing (working from sensor data, logs, and tracking anomaly patterns), for example, or working from a chatbot model (cleaned conversational data, RAG sources, and intent tagging).
Assess Your Data
Once you have some understanding of what AI is going to be doing for you, knowing your data inventory is the next step.
Starting from each use case, where are there holes or redundancies? While data warehouses are typically geared for structured or maybe semi-structured data, AI can open access to additional sources, like unstructured data, which in some cases make up 90% of a company’s inventory (and more like 50% used).
By conducting a comprehensive data inventory across your organization, you will better understand where the needed data rests now, how it moves, and how to come to address security, quality, consistency, and oversight concerns before attempting to integrate automation.
Adapt Your Data Governance for AI
Many AI solutions operate like a black box, with users understanding concepts but lacking certainty about how specific results are being generated.
This increases the necessity for companies to be able to know exactly what’s going in and what’s coming out.
The goal of a solid governance framework is to ensure availability, quality, consistency, security, and compliance, which is essential before adding potential x-factors into play.
Obviously this is even more critical for some sectors, either where accuracy is essential or regulated, such as the legal or medical fields, where HIPAA may stipulate clear obligations
Understand Your AI and Data Quality Relationship
It’s true there’s not a singular means of identifying data quality for AI—it depends on your use.
But there are issues that are problematic across the board, and standardizing formats across datasets, correcting errors, and verifying data against reliable sources ensures that issues won’t be magnified by the increased scale and speed of AI systems.
A decision on the acceptable level of quality is essential in this process, as, regardless of the sources, perfection’s impossible. Consistency begins here, with clear standards and common values.
Decide How You’re Structuring Data for AI
To generate the best possible insights, AI use may require integrating external sources you’re not using now. If you’re training AI for route optimization for logistics, for example, you may need access to real-time GPS and traffic data, in addition to the backlog of delivery records.
Can your infrastructure scale to large datasets and account for AI processing demands, or will you need additional resources?
Real-time pipelines may be necessary to take advantage of AI’s dynamism, such as for tracking anomalies from baselines, or for making real-time customer recommendations, for example.
You can also use AI-powered tools to help in this process, such as by consolidating your silos into unified systems with ETL tools or by taking advantage of third-party cloud-based solutions.
Depending on your use cases, the need to restructure to really capitalize on the capabilities may be more or less extensive.
In and Out: Metadata Management in AI
Context is critical for pretty much all effective AI use, and you can ensure readiness here by tagging your own datasets with as much detail and consistency as possible, be it sourcing, time, your own business classifications, relationships, usage rights, etc.
With AI’s capacity to work at scale, this extra layer is more essential than ever, helping sharpen responses to specific intent. Even without true reasoning at play, a quality metadata layer provides the effect of better understanding.
Ironically, as we’ve repeated in a few of these cases, AI can also help with this preparation process for AI. Machine learning algorithms can find and fix errors and flag inconsistencies, but they can also be used to automatically tag and categorize. All of this requires human oversight, of course, but can be scaled far more effectively with automation.
Clarify Your Data Security for AI
We’ve already written a prior PTP report on this topic, so take a look here for more on privacy engineering and best practices for AI data security.
In general, prioritize your data, protect it with encryption at rest and transit, clarify and stay on top of access controls, and conduct regular audits to ensure compliance.
Monitor and Maintain
None of this is a one-and-done step, and you will need to be assessing the quality of your data in and out with AI. Still, as indicated in the Wakefield Research survey, some 54% are only using manual testing or have no initiative at all in place.
Establish data quality metrics for your business to make it easier to track, ensuring that it remains accurate and valuable.
This observability is essential so that you can fix data issues before they become a problem at scale. This is an essential part of quality and governance, and once again, AI can assist in this area, helping to flag anomalies.
How PTP Can Help Ready Your Data Warehouse for AI
This is all fine to say at such a high level, but another thing entirely to execute and ensure over time, with all the unique variations and complications that come with merging the real world and the digital.
So okay, here comes the plug: because trust us, we know. Data science is one of the core pillars of what we do at PTP, with over two decades of experience providing quality tech recruiting services.
Whether your need is ensuring output data validation for AI models or the initial data preparation for machine learning, we have experience at helping companies find the best talent onsite or off.
We’ve helped organizations of various scales apply AI and ML in automating their ETL data transformation, finding and correcting data anomalies, training staff and building governance policies where they’re sorely lacking. And our specialty is helping you hire the best talent, be it in AI or data science.
Conclusion
The bottom line is that your AI success is going to be framed by your data. The power AI as an emerging technology has for acceleration, extension, and transformation is truly startling, but to take advantage, your data must be ready.
References
The State of Reliable AI Survey 2024, Wakefield Research
Accelerating AI impact by taming the data beast, McKinsey & Company
Is Your Data Infrastructure Ready for AI?, Harvard Business Review
How to Improve Your Data Quality, Gartner


